原课程地址:https://15445.courses.cs.cmu.edu/fall2022/project1/
先说感受,我确实是一个小镇做题家,做习惯了套路题再去写这种较大的文档比较困难,中间借助了大量外界的援助,此文章对于我的流程有很大的帮助,并且,我承认参考了别人的代码,之后争取独立思考以及自己debug,不过学习也是有过程的,只要有一颗热爱的心,一定能坚持下来。
那么,言归正传,p1的大纲是要求你实现一个可供测试使用的缓冲池(Buffer Pool)。
p1分为三个task:
Task #1 – Extendible Hash Table(可扩展哈希表)
Task #2 – LRU-K Replacement Policy(LRU-K删除策略)
Task #3 – Buffer Pool Manager Instance(缓冲池管理器)
然后就是并发控制
Task #1:
首先了解什么是可扩展哈希表,可扩展哈希表也是防止哈希冲突的一种哈希解决方案,我拿图举例子加以说明
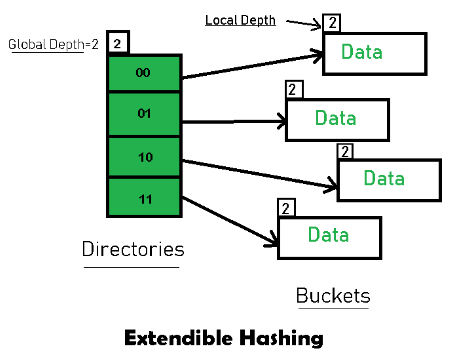
先了解目录->桶机制,目录存储着不同的索引值,通过不同的方式计算索引,同一个桶中存放的哈希值指向通用的索引值,存在全局深度,全局深度关系到目录的个数,例如图中的global depth = 2,计算出目录的个数4,桶也存在局部深度,局部深度关系到目录指向桶的个数,指向桶越多的目录数越多,说明桶内包含的有低位有效索引的数据个数越多,说明哈希表越高效。桶有一定的容积,一个桶能够承担的哈希值是有限的,这就引出了扩容机制,extended_hash_table的扩容机制如下在当存放的数据量>bucket.size()时,引出扩容机制,先看split(分裂)机制,每分裂一次,局部深度+1,分裂为两个桶,当局部深度 == 全局深度时,如果我继续插入,索引数量就不足以给哈希值分配一个地址,这个时候就要翻倍全局深度让索引值扩容,当扩容时,先取出桶的内容,然后扩容后放回原桶或者是放在新的桶,这就是可扩展哈希扩容原理,至于哈希表的另外的寻址法以及哈希表本身的原理,我就不过多赘述了。
官方文档描述的很清楚,我们需要实现的函数如下
在hash部分:
auto Find(const K &key, V &value) -> bool override;
void Insert(const K &key, const V &value) override;
auto Remove(const K &key) -> bool override;在bucket部分:
auto ExtendibleHashTable<K, V>::Bucket::Find(const K &key, V &value) -> bool
auto ExtendibleHashTable<K, V>::Bucket::Remove(const K &key) -> bool
auto ExtendibleHashTable<K, V>::Bucket::Insert(const K &key, const V &value) -> bool只重点说一下hash部分的Insert操作:
(我使用的私有变量:
(桶)
size_t size_;
std::atomic_int depth_;
std::unordered_map<K, V> container_;
mutable std::shared_mutex depth_rwlatch_;
mutable std::shared_mutex rwlatch_;
mutable std::mutex insert_latch_;(哈希)
size_t bucket_size_;
// The size of a bucket
int global_depth_;
// The global depth of the directory
int num_buckets_;
// The number of buckets in the hash table
mutable std::shared_mutex dir_rwlatch_;
// The rwlatch to protect the directory.
std::vector<std::shared_ptr<Bucket>> dir_;
// The directory of the hash table)
- 首先写锁保护目录。
- 死循环直到插入成功。
- 计算 key 的目录索引,获取对应桶和深度。
- 如果桶能插入,则直接返回。
- 如果桶满且局部深度等于全局深度,则扩展目录(加倍),全局深度加一。
- 计算桶的有效哈希值,获取桶内所有键值对,创建新桶,计算分裂后新桶的深度。
- 更新目录指针,将部分指向新桶。
- 桶数量加一。
- 重新分配原桶内所有键值对到新桶或原桶。
放一下代码部分
template <typename K, typename V>
void ExtendibleHashTable<K, V>::Insert(const K &key, const V &value) {
std::unique_lock lock(dir_rwlatch_);
for(;;){
auto bucket_index = IndexOf(key);
auto bucket = (this -> dir_)[bucket_index];
auto old_bucket_depth = bucket -> GetDepth();
auto new_bucket_depth = old_bucket_depth + 1;
if (bucket->Insert(key, value)) {
return;
}
//need split
if(old_bucket_depth == global_depth_){
auto old_size = dir_.size();
dir_.resize(old_size * 2);
for(size_t i = 0 ; i < old_size; i++){
dir_[i + old_size] = dir_[i];
}
global_depth_++;
}
auto old_bucket_valid_hash = (bucket_index & ((1 << old_bucket_depth) - 1));
auto all_kv = std::move(bucket -> GetItems());
auto new_bucket = std::make_shared <Bucket> (bucket_size_ , new_bucket_depth);
auto column_ptr = 1 << (global_depth_ - new_bucket_depth);
auto low_valid_hash_val = old_bucket_valid_hash;
auto high_valid_hash_val = old_bucket_valid_hash | (1 << (new_bucket_depth - 1));
bucket -> IncrementDepth();
for(auto i = 0 ; i < column_ptr ; i++){
auto low = ((i << old_bucket_depth) | low_valid_hash_val);
auto high = ((i << old_bucket_depth) | high_valid_hash_val);
dir_[low] = bucket;
dir_[high] = new_bucket;
}
//reinsert
for(auto &kv : all_kv){
auto key_index = IndexOf(kv.first);
dir_[key_index] -> Insert(kv.first, kv.second);
}
}
}其实原理和代码编写都还可以,灵活运用即可。
Task #2:
同样也是先了解什么是LRU-K机制
一、LRU-K机制是什么?
LRU-K(Least Recently Used-K)是一种页面替换算法,是对经典 LRU(最近最少使用)算法的扩展。
它通过记录每个页面最近的 K 次访问时间,来决定淘汰哪个页面。
二、核心思想
- LRU(最近最少使用):只记录每个页面最近一次访问时间,淘汰最久未被访问的页面。
- LRU-K:记录每个页面最近 K 次访问时间,淘汰“第 K 次最近访问距离现在最远”的页面。
也就是说,LRU-K 关注的是“第 K 次最近访问”而不是“最近一次访问”。
K 越大,算法对页面访问频率的敏感度越低,更能区分偶然访问和频繁访问。
三、算法流程
- 访问记录:每次页面被访问,记录当前时间到该页面的访问历史(最多 K 条)。
- 淘汰选择:
- 只有被标记为“可淘汰”的页面才参与淘汰。
- 对每个可淘汰页面,计算“回溯 K 距离”= 当前时间 – 第 K 次最近访问时间。
- 淘汰回溯 K 距离最大的页面(即第 K 次最近访问距离现在最远)。
- 如果某页面访问次数不足 K 次,则其回溯 K 距离视为无穷大(优先淘汰)。
- 多个页面回溯 K 距离为无穷大时,按经典 LRU(最近一次访问最早)淘汰。
四、举例说明
假设 K=2,页面 A、B、C 的访问历史如下:
- A:最近访问时间为 10、20
- B:最近访问时间为 15
- C:最近访问时间为 5、25
当前时间为 30。
- A 的回溯 2 距离 = 30 – 10 = 20
- B 的回溯 2 距离 = 无穷大(因为只有一次访问)
- C 的回溯 2 距离 = 30 – 5 = 25
此时,B 的回溯距离最大(无穷大),优先淘汰。如果有多个页面都是无穷大,则淘汰最近一次访问最早的页面。
五、优点与应用场景
- 优点:
- 能区分偶然访问和频繁访问,减少缓存污染。
- K 可调,K=1 时退化为普通 LRU,K 越大越接近 LFU(最不经常使用)。
- 应用场景:
- 数据库缓冲池管理(如 BusTub、PostgreSQL)
- 操作系统页面置换
- 需要高效缓存管理的场景
六、与其他算法对比
- LRU:只看最近一次访问,容易被偶然访问污染。
- LFU:只看访问次数,容易被早期频繁访问但后期不再访问的页面占据缓存。
- LRU-K:综合考虑访问频率和最近 K 次访问时间,兼顾两者优点。
(Andy在课程中其实也已经讨论过了,当成自己复习一遍好了),
我在头文件中,另外编写了三个工具类以供我自己使用,
嵌套类:Entry
解释:
Entry记录每个帧的访问历史。- 构造时分配历史数组,初始化各项。
- 禁止拷贝和移动。
- 析构时释放历史数组。
IsEvictable():是否可淘汰。GetEarliestTimestamp():获取最早访问时间。RecordAccess():记录一次访问,更新历史。GetSize():历史记录数。GetID():帧号。SetEvictable():设置可淘汰状态。- 私有成员包括历史数组、帧号、可淘汰标志、时间器等。
嵌套类:TempPool
解释:
TempPool用于管理一组 Entry。- 构造和析构默认,禁止拷贝和移动。
IsEmpty():是否为空。Get():获取指定帧的 Entry。Contain():是否包含指定帧。Remove():移除并返回指定帧的 Entry。Insert():插入 Entry。EvictableFront():找到第一个可淘汰的 Entry 并移除。- 私有成员:链表存储 Entry,哈希表加速查找。
嵌套类:CachePool
解释:
CachePool用于管理 Entry,按时间排序。- 构造和析构默认,禁止拷贝和移动。
Contain():是否包含指定帧。Get():获取 Entry。Adjust():调整 Entry 在 set 中的位置。Insert():插入 Entry。PopEvictedFront():找到第一个可淘汰的 Entry 并驱逐。Remove():移除 Entry。IsEmpty():是否为空。- 私有成员:set 按时间排序 Entry,哈希表加速查找。
方法都在上面有了,类中的函数我将一些较为简单的函数添加inline关键字以提高效率,用展开式的方式进行处理。
要注意,全bustub系统禁止拷贝和移动。
Task #3(缓冲池管理器):
Andy之前在课上讨论过了缓冲池如何工作,简单来说就是:我们有一个freelist(空闲列表),我进行写入时首先调用的是这些没有被写入的纯净页,如果空闲列表为空,在考虑淘汰机制,即我们前面讨论的驱逐机制(以LRU-K为例,时钟式淘汰机制我们就不讨论了,Andy同样在课上进行了详细的介绍)。在驱逐脏页时,我必须要进行写回,即:将驱逐的Dirty page(脏页)中写入的数据写回磁盘,然后重置页码、内容、内存分配,这同样也是task3的中心内容。
那么对于task3,我认为虽然细节虽然较前两个多,但是整体的思路也不算很难(应该是对于我最友好的任务了)。
写一下比较麻烦的函数FetchPgImp(page_id_t page_id)-> Page*{}
(引用一下别的小伙伴的博客内容,原文章:https://blog.csdn.net/AntiO2/article/details/128554356)
FetchPgImp传入一个page_id,并返回对应页面的指针。
如果通过hash表查到该page在内存中,直接返回,记得LRU-K记录一下访问历史。
FetchPgImp驱逐过程和上一个方法类似。但是要加一步:从磁盘中将之前的data读入内存
disk_manager_->ReadPage(page_id,pages_[frame_id].GetData());
注意
如果要fetch的页面已经在pool中了,那么要进行以下操作
lru-k要进行record
手动setEvictable为false
pincount++
如果不在pool中,那么也要进行以上操作,并且pincount = 1
上面这个卡了我很久,因为在文档里也没写具体的要求,大家写的时候注意一下
————————————————————————————————-
然后放一下本地测试吧
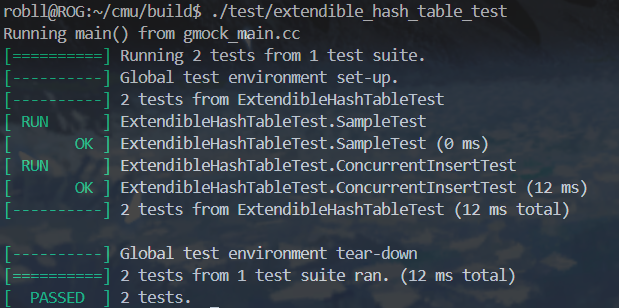

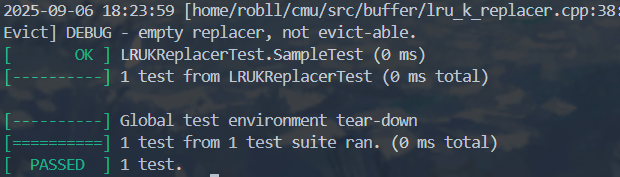
也算是将就通关了,继续学习接下来的内容,下期见了朋友们
Ciallo~(∠・ω< )⌒★
